
To reach our goal of 99.99% availability, we implemented various strategies, focusing on improving production stability as a key measure.This blog post will delve into the initiatives we undertook to improve the production sanity environment.
Major challenges commonly faced in creating an effective environment for production sanity include:
A. The rapid pace of development cycles among teams often leads to inconsistencies in the environment designated for production stability checks.
B. The absence of an environment that mirrors the production setup, both in structure and volume, mainly due to the high costs associated with maintaining replicas that are synchronised with the actual production environment.
In response to these issues, we initiated a series of brainstorming sessions to clearly define the problem and develop effective solutions.
What are we trying to solve?
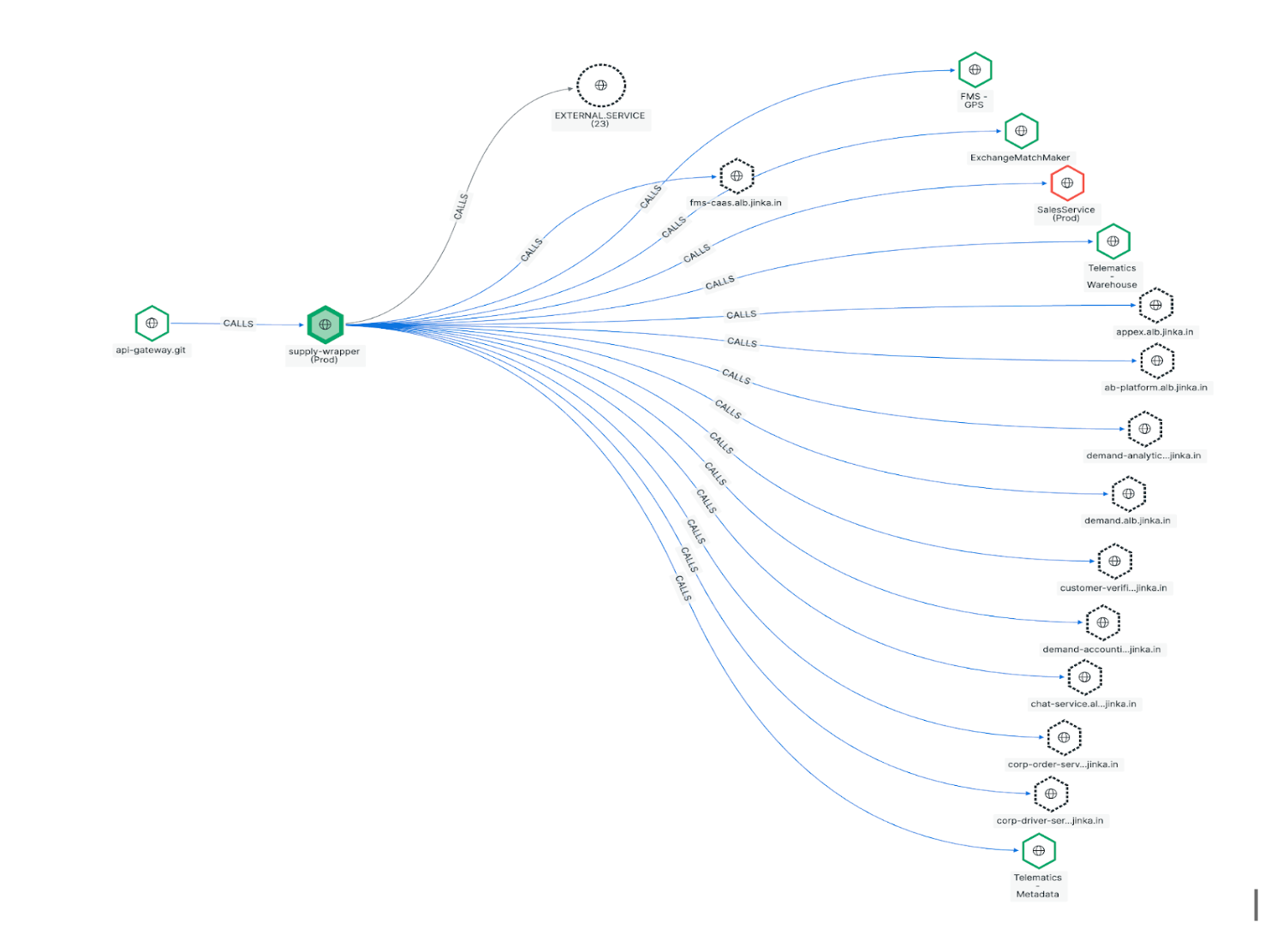
Inter Service Dependencies
With hundreds of services undergoing continuous development, it becomes challenging to conduct production sanity checks in isolation.
Data sanity
Maintaining In-Sync Replicas to ensure data is synchronised with the production environment for staging can incur significant costs.
Environment sanity
When each service team tests their features concurrently on the staging environment, it can present significant challenges in preserving the integrity of the codebase.
Limited time for production sanity
When the staging environment fails to accurately replicate the production environment, production sanity checks must be conducted directly in the production setting. This constraint imposes strict time limitations for testing and necessitates conducting User Acceptance Testing (UAT) during off-peak hours.
Enter Rush_Env !
Considering above challenges we need to come up with an environment which mirrors production in data and code, easy to maintain in line with production, and short-lived.
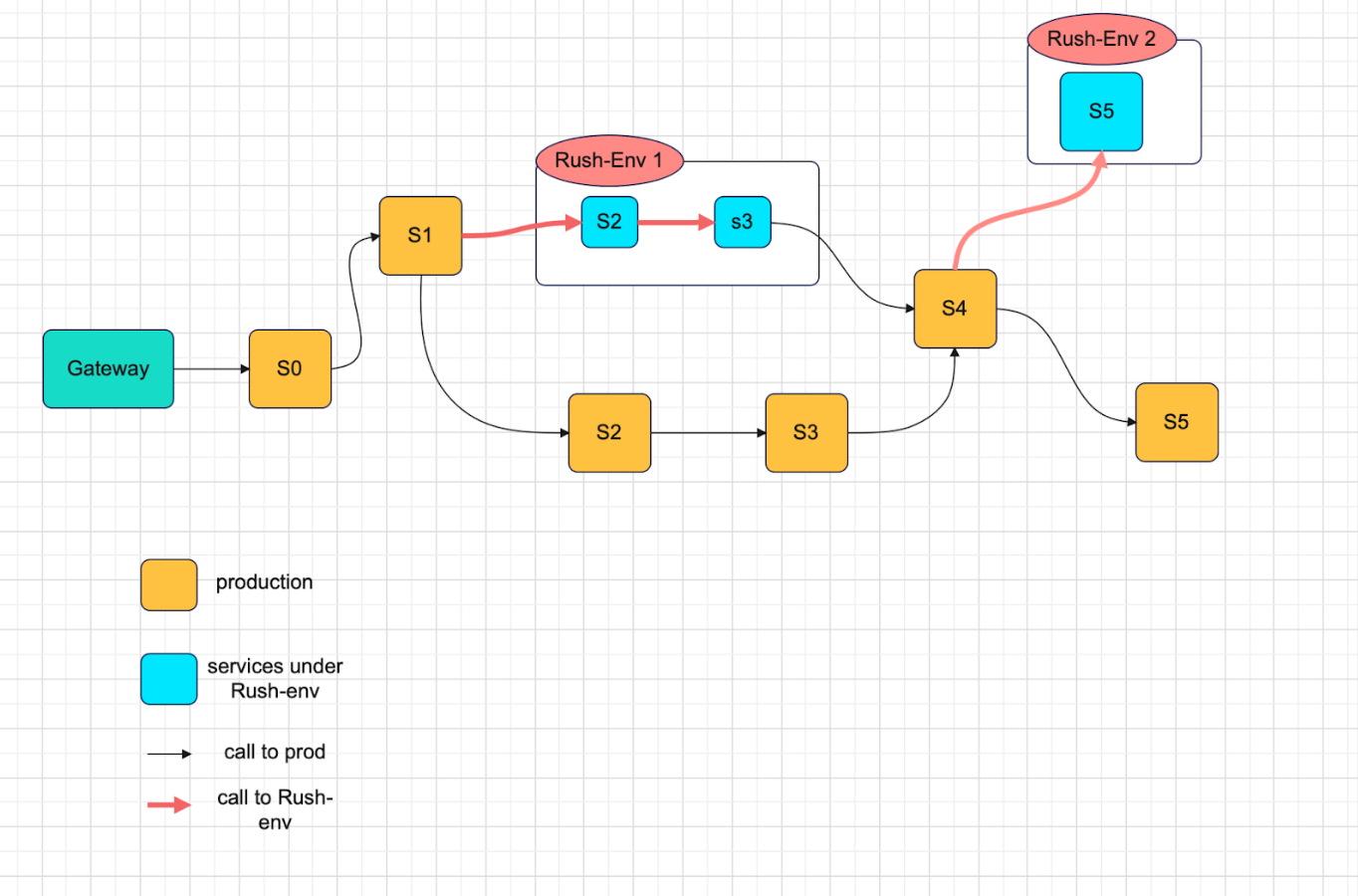
The architecture of our system was based on following goals :
- User-Specific Routing: Routing traffic for a set of users on specific services .
- Service Instance Multiplicity: Different instances of service can be spawned simultaneously to test different features in isolation.
- Flexible Request Routing: Route user requests to instances of services in different environment based on headers present in incoming request.
- Production Data Testing: Using the same data stores as production.
- Regression Testing Environment: Creating environment which gives a platform to perform regression as well as UAT for any amount of time.
- Independent Monitoring and Alerting: Separate monitoring and alerting framework to facilitate distributed tracing and monitoring.
By focusing on these design goals, we aim to create a more resilient, flexible, and user-centric system.
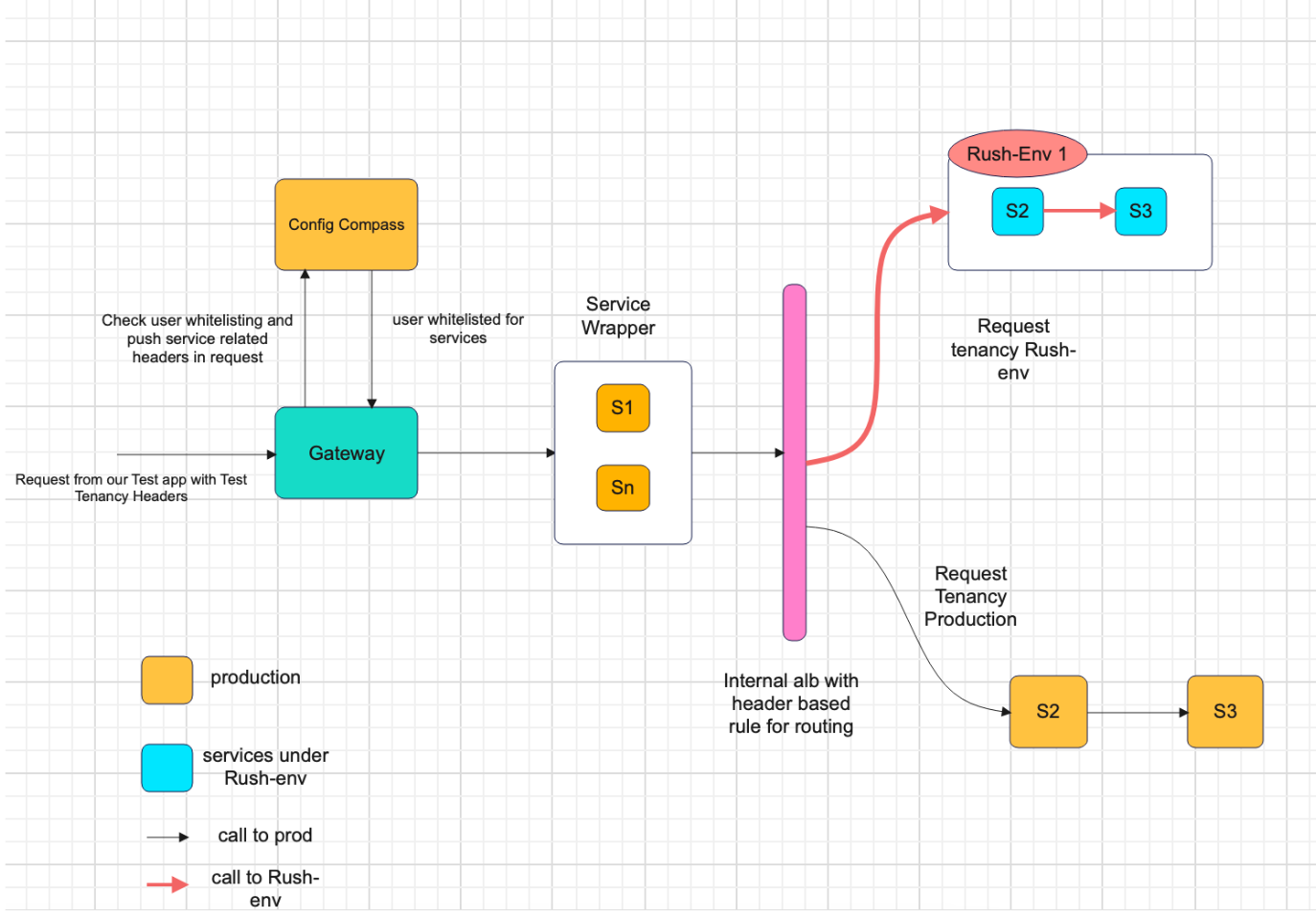
Implementing user-specific routing to direct certain users to our Rush Environment (Rush_Env) in AWS EC2 involves following components:
- Config Mapper Service: This service enables the QA team to whitelist specific users for production sanity checks. Essentially, it identifies users whose traffic should be directed to our Rush_Env rather than the production environment.
- Alpha Android Apps: Alpha versions of our Android applications. Having the ability to insert a static header into all outgoing requests.
- AWS Target Group and ALB Routing: Aws target groups and Alb routing rules to route requests to different instances of services.
- Spring Filters in API Gateway: Within our in-house API Gateway, we integrated Spring filters that can interpret the static header from the Alpha app and adds Request tenancy headers in all outgoing requests.
- Custom Library Integration: A custom library to be integrated as Gradle transient dependency. which is responsible for recognising and propagating the relevant headers downstream.
- Distributed Tracing: To support distributed tracing and alerting, the library utilises Open Telemetry and Jaeger packages to trace requests that carry the designated headers and push the traces to tempo to be monitored through Grafana.
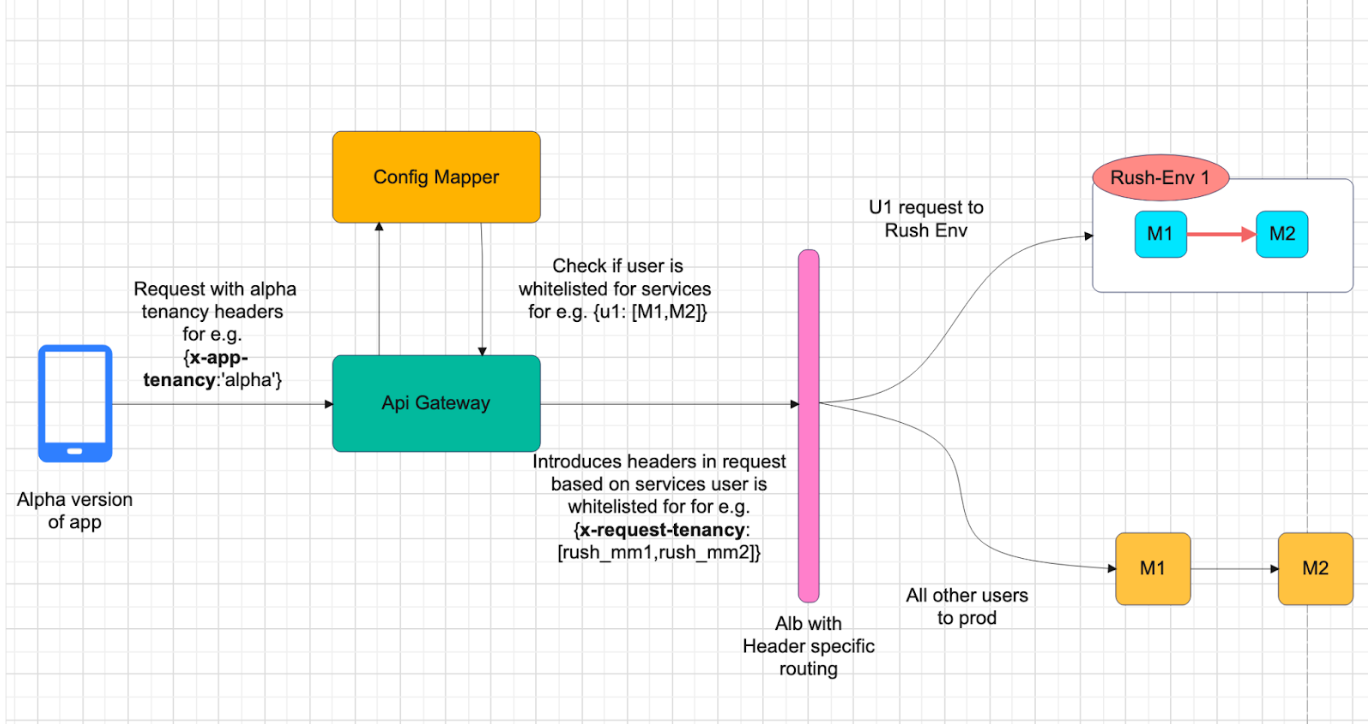
User Whitelisting for Rush_Environment
For prod sanity and in order to allow user specific traffic to be routed to Rush_Env we need to perform following steps:
- Config Compass Service: This service takes care of whitelisting of users for a set of services.
For e.g. if User U1 needs to be tested for services(M1, M2) for production sanity. QA will whitelist the user for these set of services in config compass. - Users traffic based on service it is whitelisted for will be routed to Rush_Env of those services. Rest of the services will be of production only.
- Users can be whitelisted for any number of services to facilitate any P&Cs of routing in production and Rush_Env of services.
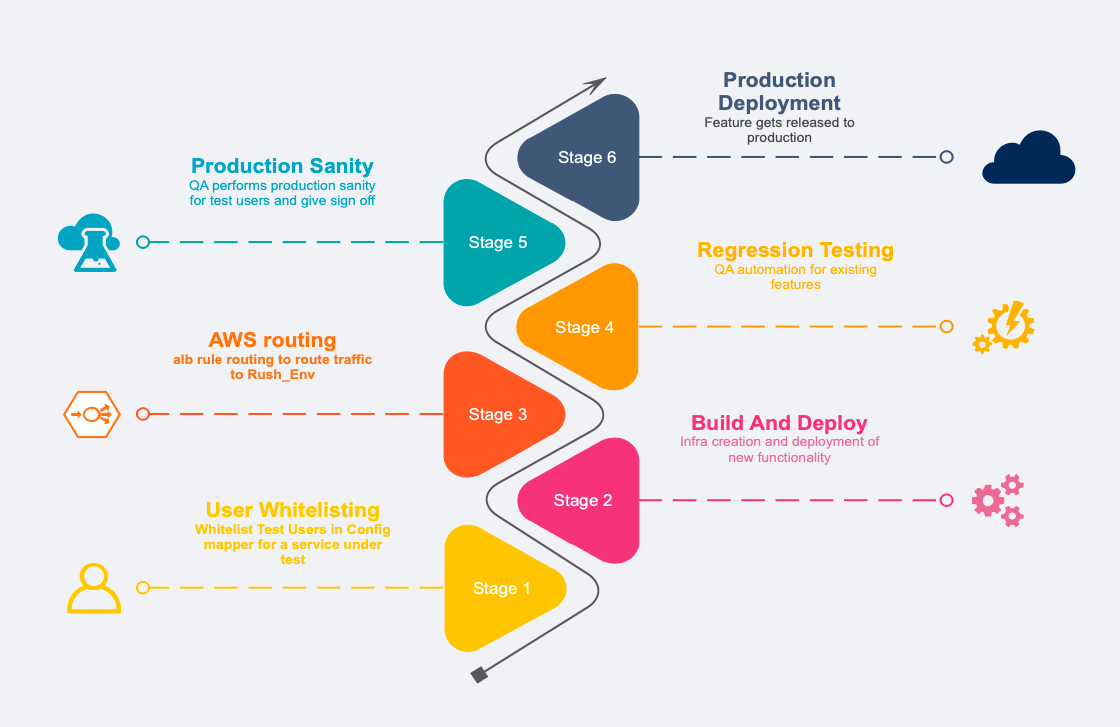
Deployment Procedure
Here's how the deployment process with Rush Environment unfolds:
- Initiating Deployment: Upon deployment Rush_Env of our service get created and new code will get deployed on it.
- Registering the New Instance: The newly created instance will get registered under a new target group.
- Configuring Load Balancer Rules: A new routing rule is added in the load balancer. This rule is responsible to direct requests to the new target group for whitelisted users.
- QA Automation Testing: After Rush Environment setup is done and application is healthy, QA automation for regression are triggered.
- Publishing Test Reports and Manual QA: After the automated tests complete, the results are compiled and published.
- Manual Approval for Production Deployment: Following successful QA checks, a manual UAT is done. post that manual intervention from QA is needed to allow the CI/CD pipeline to proceed to the next stages.
- Cleanup After Deployment: Post-deployment to production, a cleanup job is automatically triggered. This job performs several important tasks:
A) Destroys the infrastructure set up for the specific Rush Environment being tested.
B) Deletes the target group associated with the tested service.
C) Removes the custom routing rule from the load balancer to ensure it doesn't affect subsequent production traffic or incur unnecessary evaluation overhead.
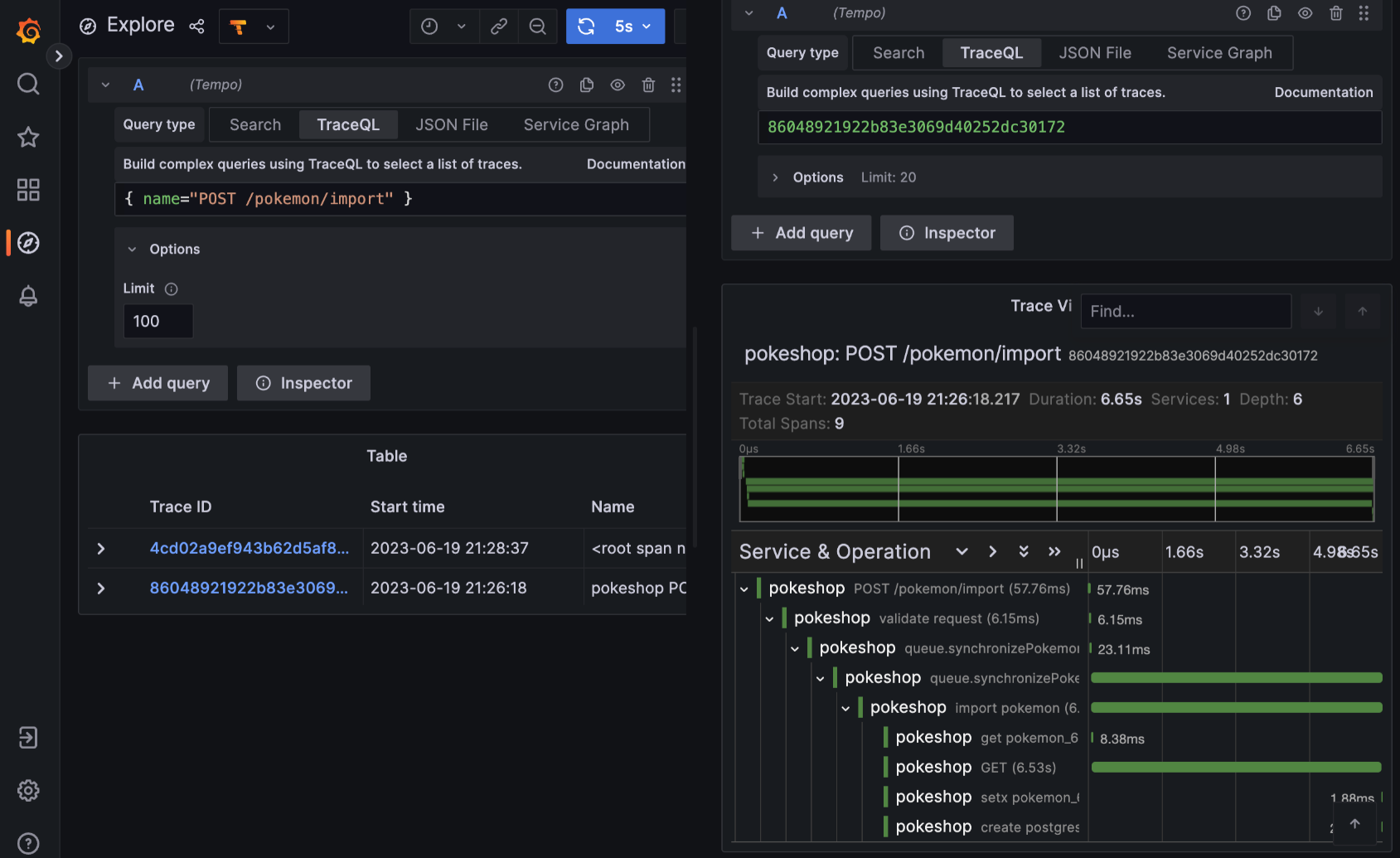
Distributed tracing, Monitoring and Alerting
For our Rush_Env, we wanted to have more aggressive monitoring and alerting capabilities. To achieve this we created a library which takes care of :
- OpenTelemetry for Distributed Tracing: We utilised OpenTelemetry to facilitate distributed tracing across all our services, for request having tenancy-based headers.
- Tempo as the Trace Collector: Tempo, a high-scale, minimal-dependency trace collector, was chosen to aggregate the traces gathered through our distributed tracing setup.
- Prometheus for Time Series Data: To manage the time series data generated from our traces, we integrated Prometheus into our architecture.
- Grafana for Monitoring and Visualisation: We are using Grafana for our monitoring and alerting setup.
Rush_Env in Kafka:
Post solving for web throughput our next goal is to achieve similar functionality in non web especially Kafka.
Objectives
- Production Sanity Framework for Kafka Consumers and Producers.
- Avoid Consumer Rebalancing in Production.
- No extra Code Changes for Consumers/Producers.
Testing Scenarios
The testing for Kafka within the Rush_Env will cover various combinations of producers and consumers to ensure comprehensive coverage:
1. New producer + New consumer
2. Old producer + New consumer
3. Old producer + Old consumer
4. New producer + Old consumer
Proposed Solution
- Prod+1 Environment for Consumers: By running consumers in a prod+1 environment, we can simulate the production environment closely while isolating the impact of testing.
- User-Specific and Service-Oriented Consumer Implementation: Implementing consumers in the prod+1 environment that are specific to the user and service under test allows for targeted testing of Kafka interactions.
Current Limitations
- Third-Party Callback Events: At this stage, we are not addressing the testing of third-party callback events within the Rush_Env.
- Events Outside Services Scope: The solution does not currently cover events originating from sources other than services, such as Maxwell or database triggers.
Changes we planning to make
Producer Library
- Integration with Config Mapper Service: The producer library will first communicate with the Config Mapper Service to determine if a user is whitelisted for certain services.
- Context Injection into Messages: For whitelisted services, the library will inject a specific context into the message payload. For example, it might add
{"event_tenancy": "U1_S1"}to indicate the message is intended for a specific tenant or environment. - Dual Cluster Event Pushing: Once the context is injected, the producer will push the event to both the production and Rush_Env clusters. This ensures the message is available in both environments, but only acted upon by the intended recipients.
Consumer Library
- Event Tenancy and Environment Awareness: The consumer library is designed to understand the event tenancy context and differentiate between the Rush and Production environments.
- Selective Event Consumption: In the production environment, the service will ignore events tagged with a tenancy context indicating they are intended for the Rush_Env. This prevents duplicate processing and ensures production workflows remain unaffected by testing activities.
- Rush_Env Event Consumption: Conversely, in the Rush_Env, services will recognise events marked with their specific tenancy context and consume them accordingly. This allows for targeted testing of changes without impacting production data or processes.
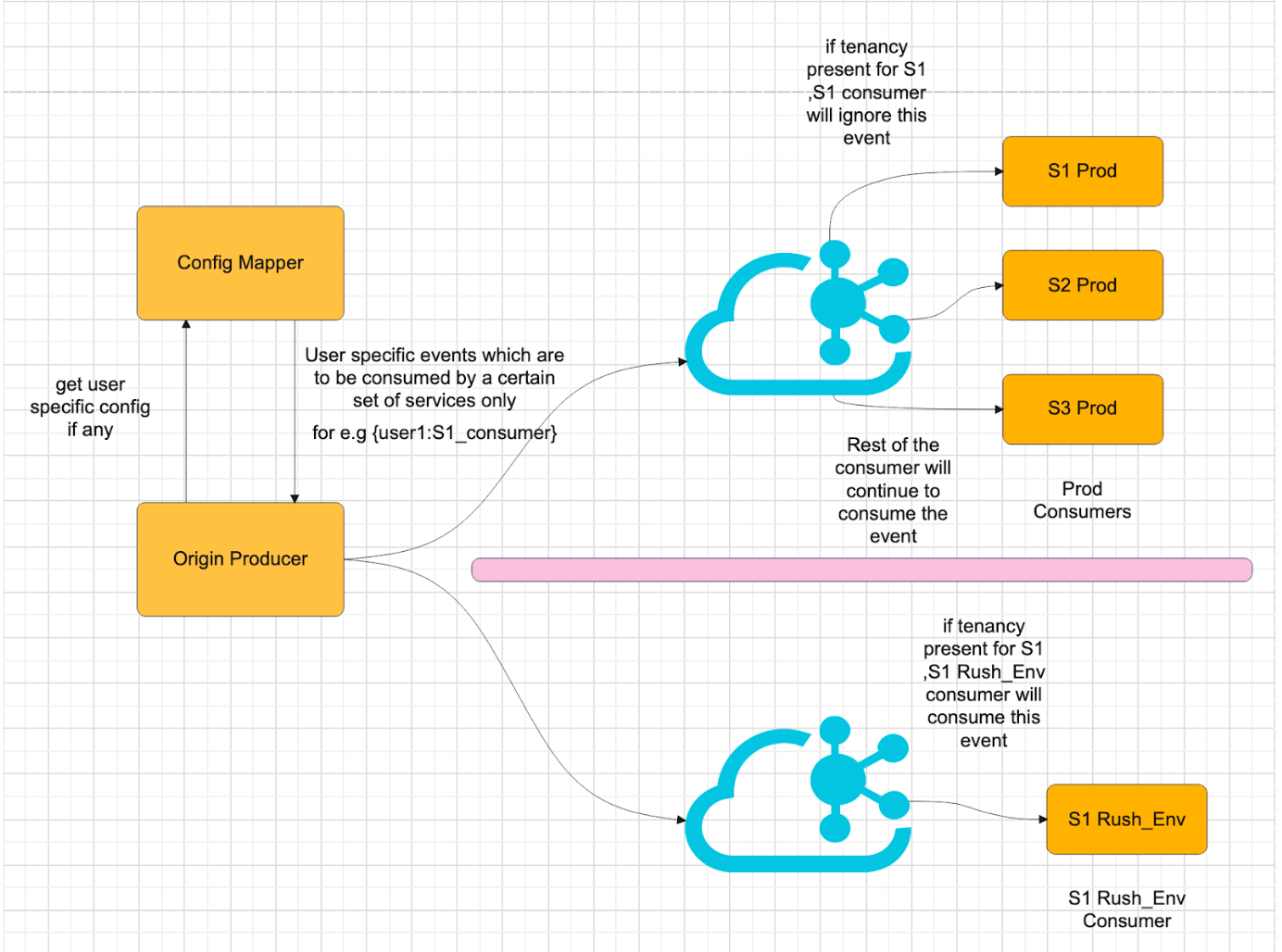
Operational Flow
- Event Generation: A producer, upon determining that a user or service is whitelisted for Rush_Env testing, injects an event_tenancy context into the message and sends it to both clusters.
- Production Consumption Logic: Production consumers, upon receiving an event, check the event_tenancy context. If the context matches their own identification and having tenancy of Rush_env, indicating the message is intended for Rush_Env consumption, they ignore the event.Rest of the services checks and finds out context is not theirs they continue to consume the event.
- Rush_Env Consumption Logic: Rush_Env consumers, recognising an event tagged with their tenancy context, consume and process the event as part of the testing workflow.
This dual-library approach with intelligent event routing based on tenancy and environment context ensures that our Kafka-based messaging system can support dynamic, environment-specific testing without interfering with production operations. It facilitates a robust testing framework that allows for comprehensive validation of new features and changes in an isolated yet realistic environment.
Stay tuned as we continue to innovate and share our journey, hoping to inspire and contribute to the broader tech community. Our adventure into optimising Kafka for our Rush Environment is just one of many steps we're taking towards building more resilient, efficient, and user-centric software solutions.