
Introduction
Agility, rapid iterations, and a focus on quickly delivering value to customers are some of the key cultural traits of the technology team at BlackBuck. Most often at BlackBuck, the time to market for any piece of code written by developers is less than a month. This means that individual contributions are more visible and can have a significant impact on the product and company. Our developers appreciate this sense of autonomy and the ability to shape the direction of the project. Such a culture of innovation also provides developers the opportunity to work on cutting-edge technologies and solutions, as well as the creative freedom to experiment with new approaches.
As BlackBuck transformed itself into a multi-category (Fastag, Fuel, GPS, Loads Marketplace, Financial Services, Used Trucks Marketplace) business supporting multiple tenants (Demand, Supply, Sales), it became imperative for us to maintain the integrity and high availability of production systems. Our products are now deeply integrated into the daily operations of each of these tenants. This transformation needs to be supported by a highly available backend system as any downtime has a direct and measurable business impact (loss of revenue, loss of sales, degraded customer experience, low conversions etc.) for each of the categories and tenants. Hence, finding the right balance between agility and system availability was essential for our success. In this blog post, we discuss how, at BlackBuck, we achieved this balance while maintaining a developer culture of freedom, innovation, and rapid iterations.
Defining High Availability Needs
We started by first defining the availability requirements for different business categories. We soon realized that different parts of the business and in turn the different components of the system may have different availability requirements. It is important to correlate availability metrics with business metrics to come up with the correct availability requirements aligned to business needs. To understand this, we looked at how every system’s downtime will impact key business metrics around customer experience, customer churn, loss of revenue, decreased customer activity and loss of sales team productivity. For example, x minutes of downtime on one of our platform microservices will have the following financial impact :
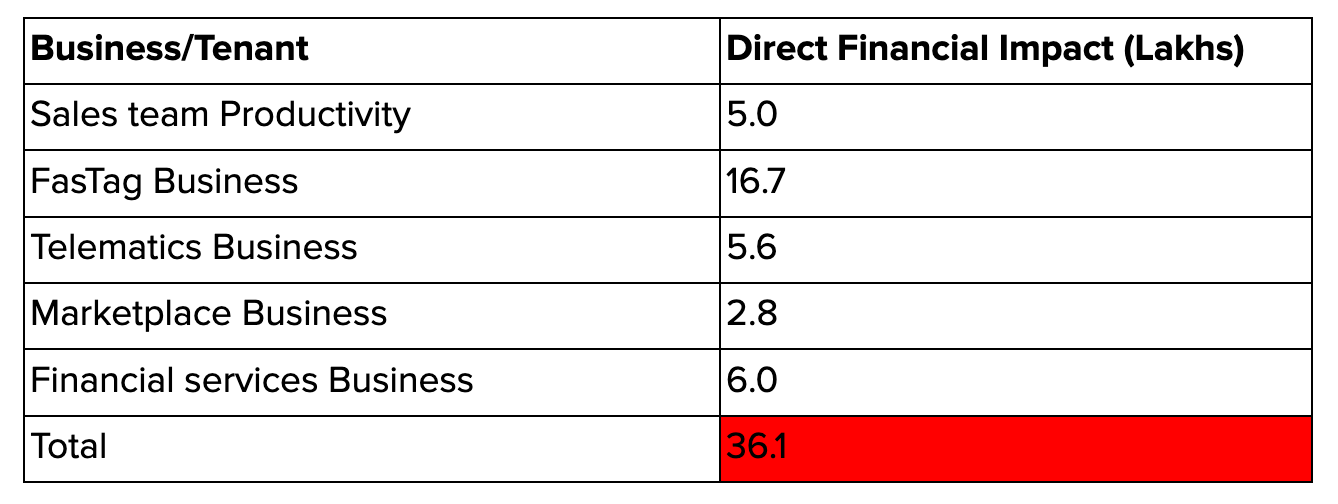
Based on this analysis for business metrics for different business and product categories, we defined availability SLA targets of 99.99% availability for many systems powering our core product features like FasTag balance/recharge, GPS live location, Marketplace load search, Order placement etc. We also humbly accepted that we are also OK with having lower SLAs of 99.9% availability for many other systems supporting features like monthly/yearly ledgers and invoices etc.
Understanding and Fixing Gaps in the SDLC
To achieve our target of 99.99% availability, we reviewed our entire SDLC process and came up with action items at each step. By continuously improving our system architecture and operational excellence processes over the years, we were able to reach availability of 99.95% for most of our systems. We observed that most of the downtimes now were happening due to bad releases and root cause were often manual misses. The Mean Time to Detect and Mean Time To Resolve for these manual misses were also on the higher side. So, we started digging deeper into our release processes as well.
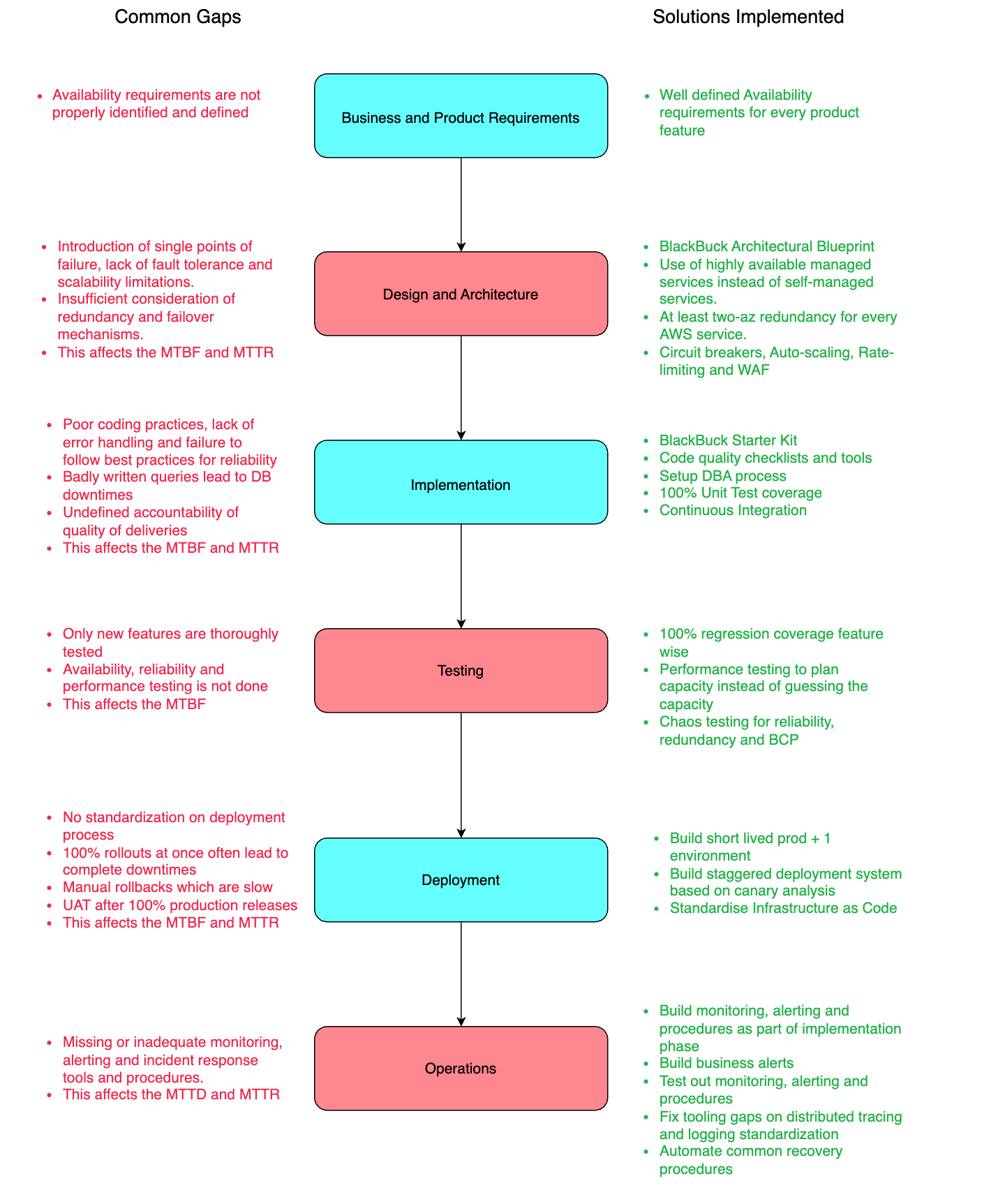
Understanding Gaps During The Release Phase
Every piece of software system which is in active development exhibits a failure pattern as shown in the figure below. After the initial burn-in period, the availability of the system stabilizes at a baseline. Every release after this period can potentially introduce new faults in the system and the overall system failure rate may see a spike in every release. This means that frequent releases can make the system more likely to experience availability issues.
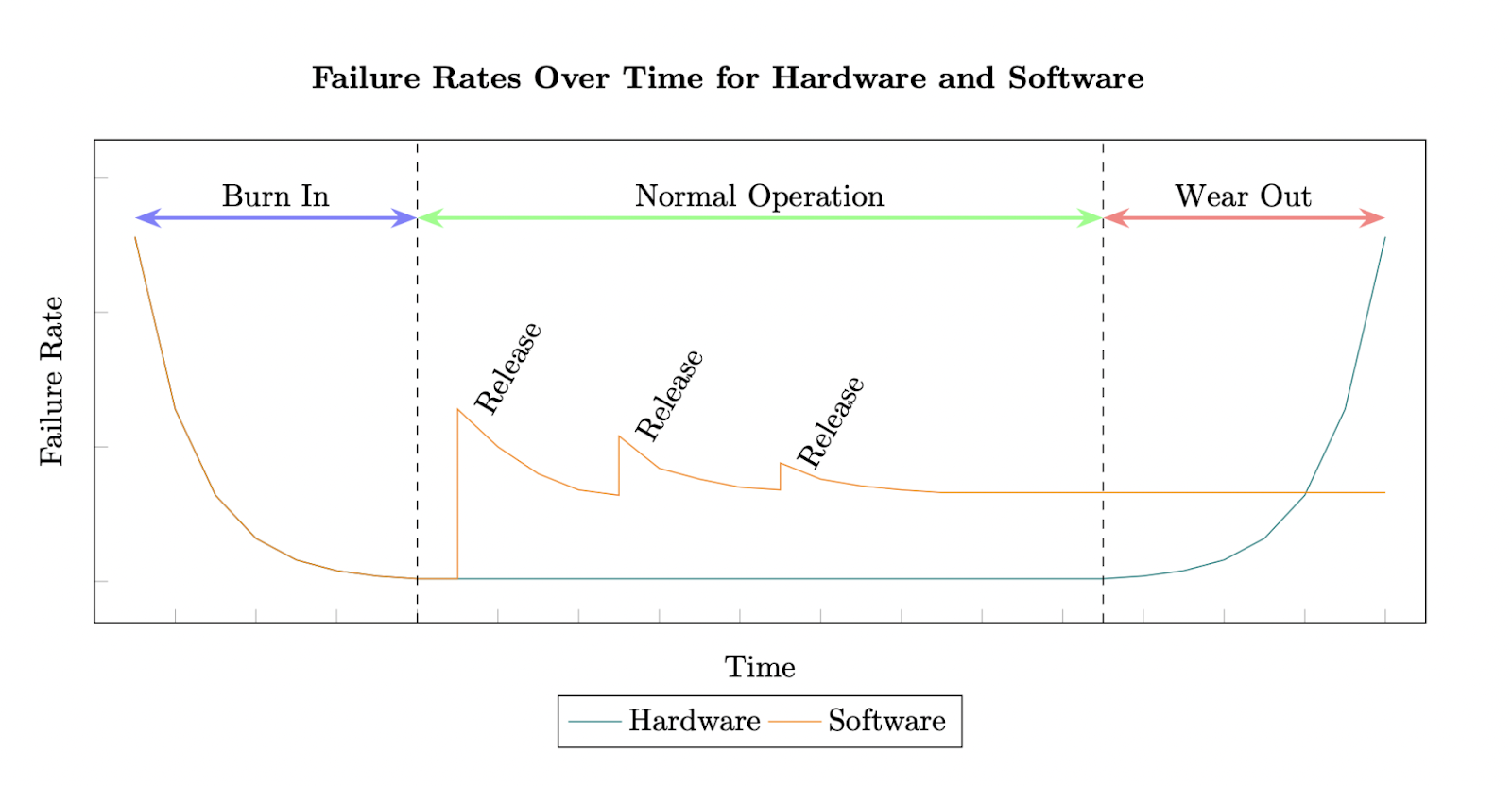
To understand how releases were impacting availability at BlackBuck, we reviewed the RCAs for all of our past downtimes and came up with solutions at each phase of the software development life cycle. This blog specifically focuses on the solutions that we figured out during the different stages in our release phase.
Some gaps we identified in different stages of our release phase were as follows :
- Functional Testing misses : During the testing stage, we focused on thoroughly testing the new changes. We were also doing manual sanity checks for ensuring that there is no impact of these news changes on the existing user flows. This process was prone to manual misses and there were chances that a bad release impacting the existing features was only being caught after a production rollout.
- Variability in Deployment Processes : While we had robust CI/CD pipeline built using Jenkins and Ansible, there was a diversity in the implementation process. Different teams adjusted the pipelines to suit the nuances of their service architectures, occasionally resulting in deployment challenges. Additionally, during significant releases encompassing multiple interconnected services, the existing pipelines did not strictly enforce a uniform order of deployments.
- 100% Traffic Rollout at once on new release : We were rolling out 100% traffic in one go to the new release. This meant that any bug in the new release could potentially impact all users before being caught.
- No separate UAT environment : UATs were being done in the QA environment. In presence of multiple releases, sometimes it becomes difficult to maintain the sanity of the QA environment and could lead to UAT misses.
- Manual analysis of system metrics : After every release, we were comparing pre and post release key system and business metrics from our observability tools manually. As our systems matured, we were tracking a lot of metrics and manually analysing all the metrics became infeasible.
- Manual interventions for rollbacks : In case we observed failures after any release, manual interventions were needed to roll back the changes which affected the mean time to recovery.
Solution for Fixing the Gaps During The Release Phase
To address these gaps, we came up with the following solutions :
Automation Testing : We decided to build 100% regression coverage for all our features with an SLA of 99.99% availability. We also integrated the automation suite in our CI/CD pipelines and ran the automation test suites with actual production data and test users. This ensured that no code was going into production without passing the automation tests.
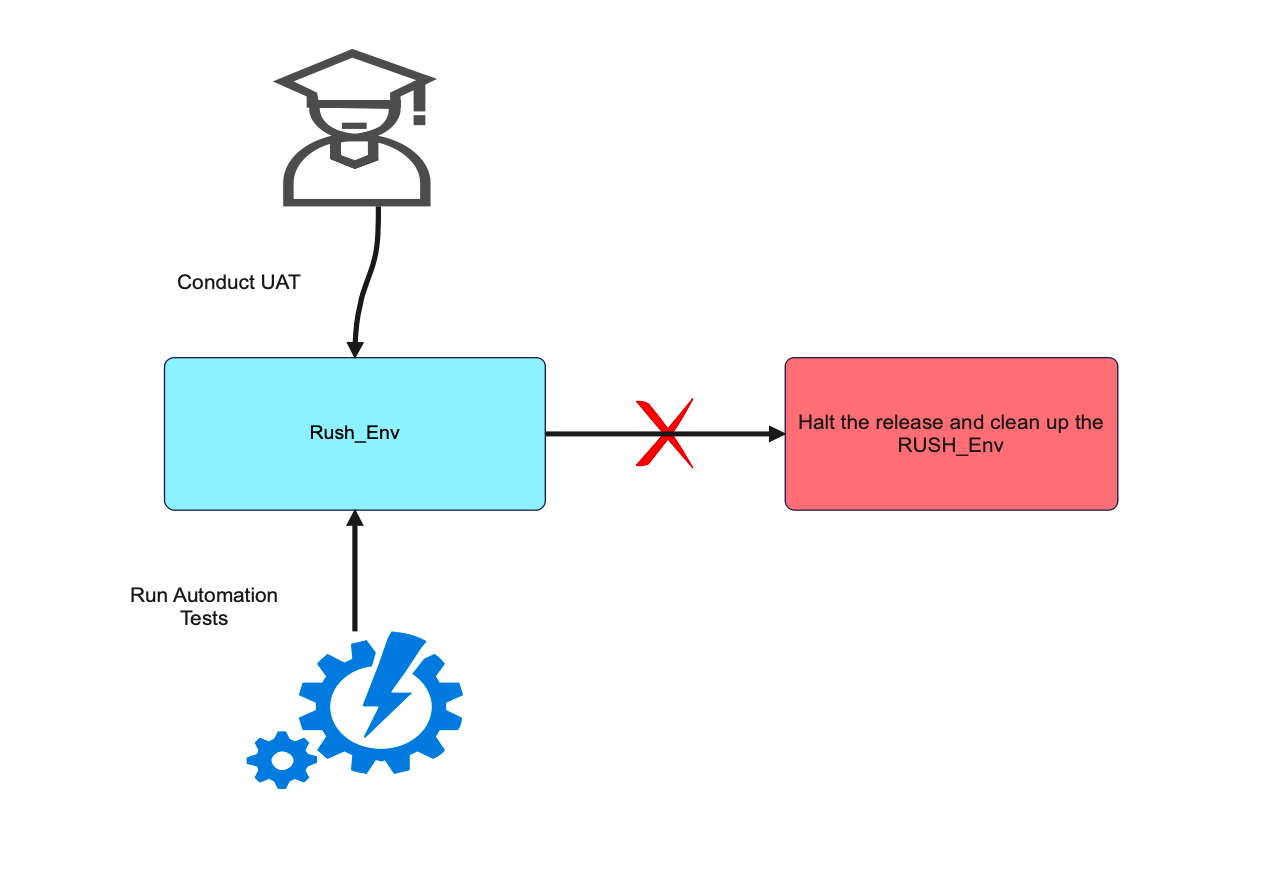
Request Header-based User Sanity Helper Environment (Rush_Env) : We built a new short lived environment called Rush_Env to have the capability to test production + 1 changes with production data and test production users. This environment provided fine grained control to route requests to either production or production + 1 in a microservices environment even if the requests were spanning across multiple microservices. This helped us to run automation tests and UAT on production data and test production users without impacting the real users. Read more about how we built this here.
New CI/CD Platform : We built a modular CI/CD platform with plug and play libraries to easily create and deploy new pipelines.

Infrastructure as Code : As part of this new platform, we also implemented standardized Infrastructure as Code practices through the utilization of Terraform.
Modularity and feature releases : The modularity of the platform allowed us to adopt Pipeline as Code and easily create new deployment pipelines consisting of multiple deployment across multiple services. This helped in standardizing our deployment process for big feature releases.
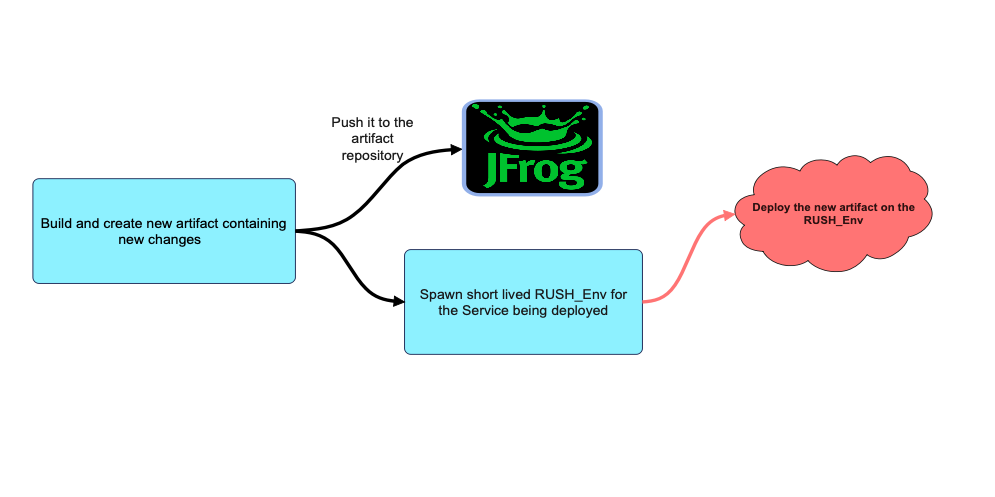
Automation Testing, UAT and Rush_Env : We also integrated an automation testing framework and the creation of Rush_Env to run the tests and UAT during any release.
Phased rollouts : This new platform also ensured that every production release was rolled out in a phased manner by employing a blue/green deployment strategy.
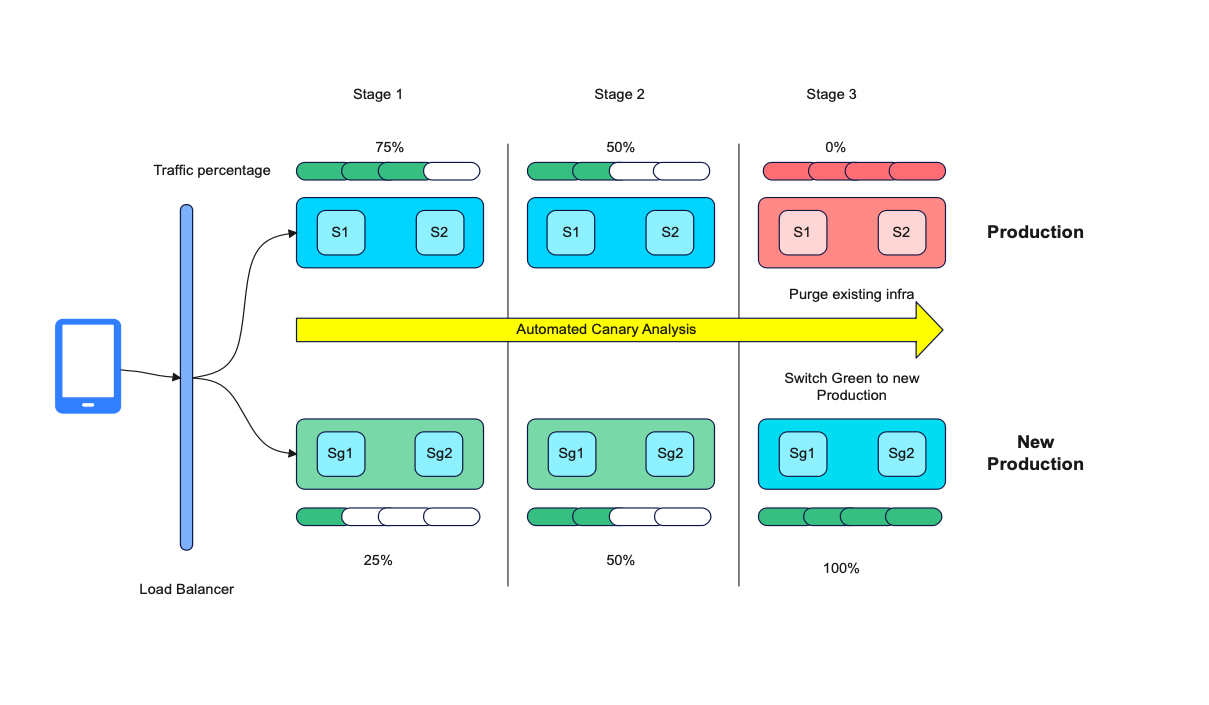
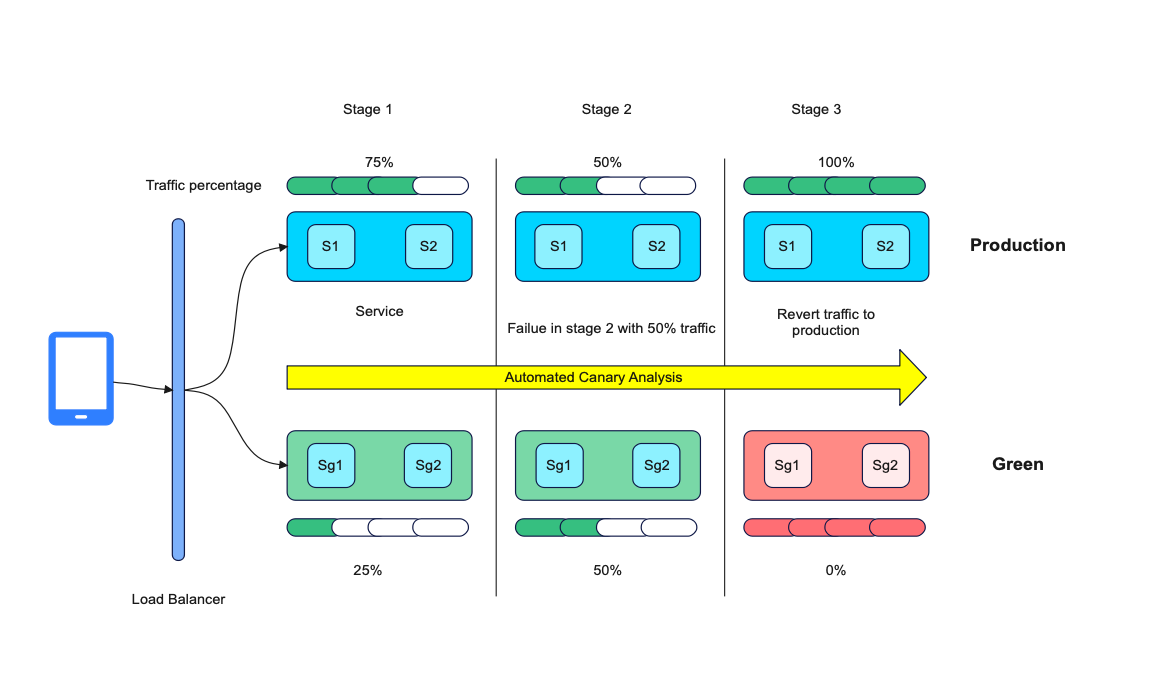
Automatic Canary Analysis and rollbacks : We also used Kayenta to conduct automatic canary analysis of key metrics by integrating it with our Observability tools. These analyses are done after every incremental rollout and in case of deviations, the changes are instantaneously rolled back. This helped in solving the gaps in manual analysis and manual rollabacks.
Release Cycles After Implementation of the Solutions
After implementing all the solutions identified during this process, this is how our overall release cycles look like now.
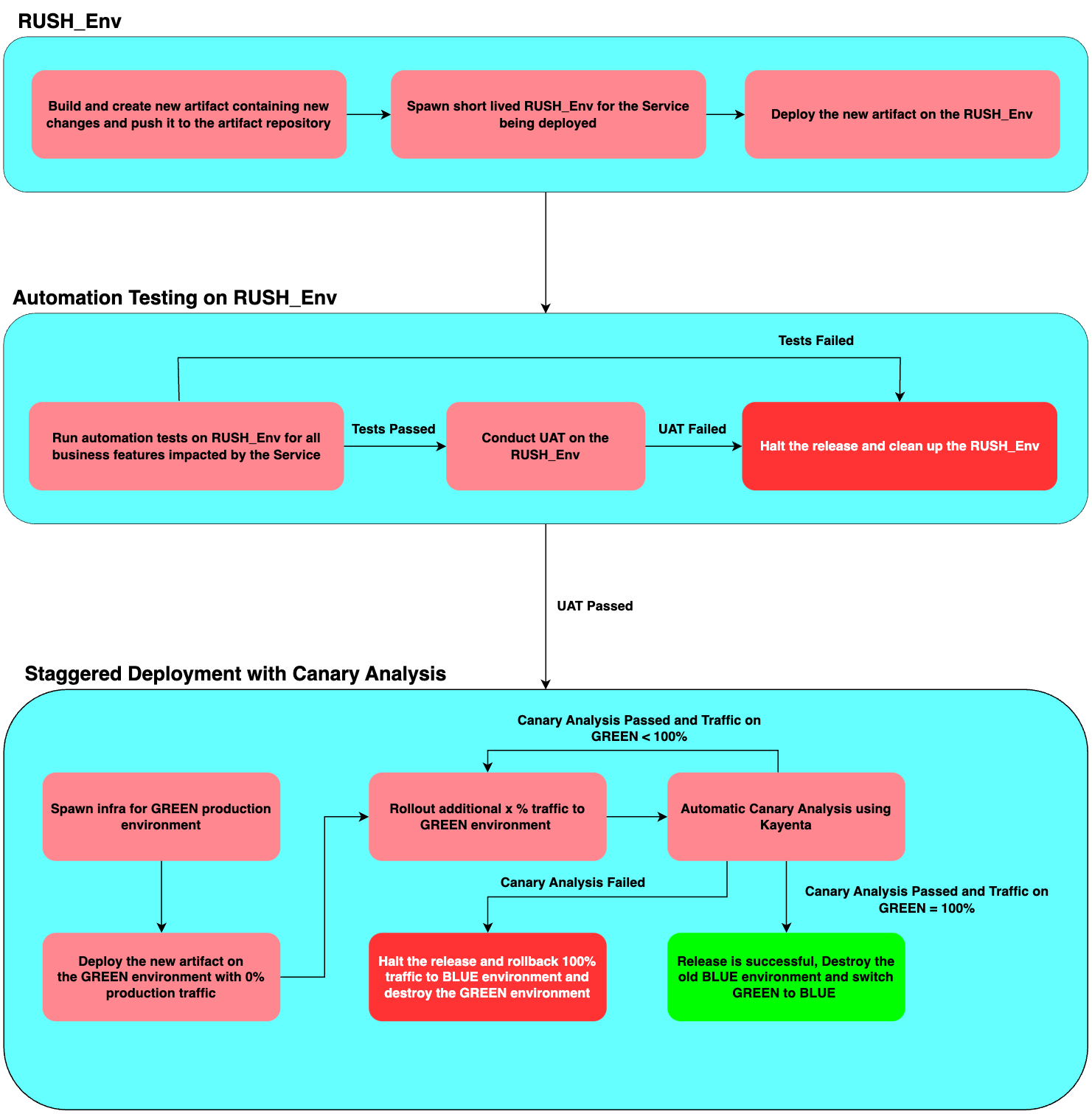
Here are a few snapshots of the successful and failed releases.


Conclusion
BlackBuck's agile development culture and a commitment to achieving 99.99% system availability exemplifies the successful balance of innovation and reliability. By aligning availability SLA targets with business metrics, we addressed gaps in our SDLC, implementing solutions like automation testing, Rush_Env for user testing, and a modular CI/CD platform with staggered deployments and automatic canary analysis.This helped us to attain improved release cycles, reduced manual intervention, and enhanced system reliability.
This blog provides only a high-level overview of our approach and overall solution architecture. Stay tuned for more in-depth insights through upcoming technical blogs, where each of the solutions mentioned above will be explored in detail.
References
 Availability and Beyond: Understanding and Improving the Resilience of Distributed Systems on AWS
Availability and Beyond: Understanding and Improving the Resilience of Distributed Systems on AWS Netflix TechBlog
Netflix TechBlog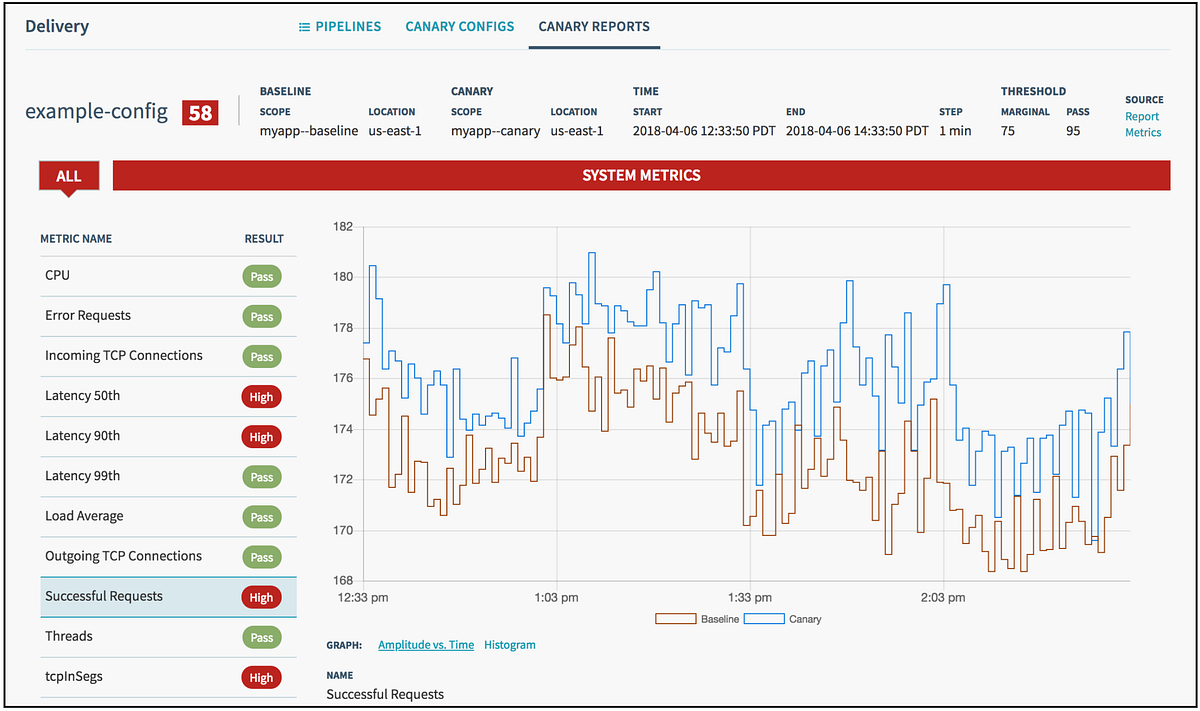
Uber Engineering Blog : Simplifying Developer Testing Through SLATE
Title image by Photoholgic on Unsplash
