

BlackBuck provides Tolling services via the Boss app. On this app, trucker can purchase toll tags(FASTags), get it delivered, recharge, view all transactions/ledger, schedule recharges, get credit, apart from interacting with plethora of other services like Fuel, GPS, Load Booking etc.
Blackbuck has been providing tolling services much before the Government impetus on mandating FASTags on national highways. Our platform saw a huge surge in FASTag purchases and transactions, 2-3 months prior to December 2019 (initially set as a cut-off date for mandatory use of FASTags). Number of transactions per minute grew almost 10x. This brought along lot of technical challenges and we had to ensure our systems were scalable without compromising on user experience.
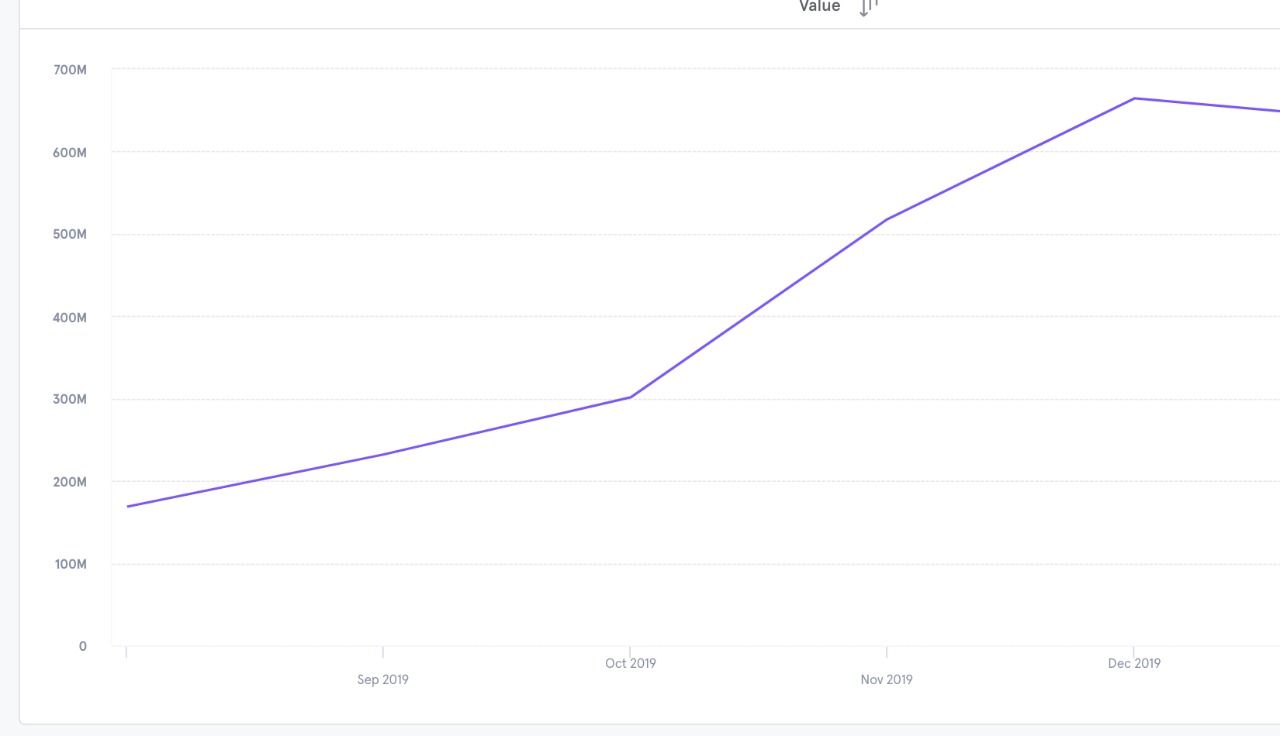
Around October, we came up with the framework of optimisations to ensure our systems could scale.
Breaking the monolith
Toll service had to be an independent service running on its own EC2 boxes on AWS. If it were part of a monolithic system, any change to non-toll features would risk bringing down toll functionality.
At BlackBuck we already had Toll server running in microservice architecture model. But the DB was part of a cluster which were running on same AWS RDS. The risk here were:
- If there's a bad query on Master/Slave, it will choke up entire RDS inadvertently bringing down toll system which will be waiting on RDS to execute SQL queries.
- If some activity (long running) holds up a socket connection to RDS, then the number of connections will keep increasing as time progresses because of high RPM (Request Per Minute Throughput).
- Frequent spikes in CPU can cause CPU credits to exhaust on T3 series boxes of RDS.
All these lead us to separate Toll DB to RDS of its own running on Master - Slave architecture. Since the RDS doesn't support multi-master configuration, we need to ensure near realtime DB migration which isn't easy. Below image shows steps taken for this.

You can read more about this here
Remove Cyclic Dependency
Toll service calls many dependent microservices to carry out numerous transactions. For ex: Whenever Toll recharge happens, Toll service get meta data about the user trying to recharge from FMS (Fleet Management Service). It then talks to Payment Service to debit the amount from user's account and transfer that to Toll tag. On success, it will update Toll Service and simultaneously push the event to Kafka Cluster which is then consumed by downstream systems.
Cyclic dependency in its simplest form is when Service A calls Service B which in turn calls Service A for getting more info. If cyclic dependency exist in BlackBuck's servers, then any service on which Toll is dependent on can cause Toll service itself to crash if said service has issues. This leads to cascading server failures. Within BlackBuck commerce systems, there are about 30+ interconnected micro services and detecting such dependencies for all APIs is not easy. To detect and prevent, we implemented Zipkin for our servers. Zipkin in a Distributed Tracing service which also generates dependency graphs as log flows through it.
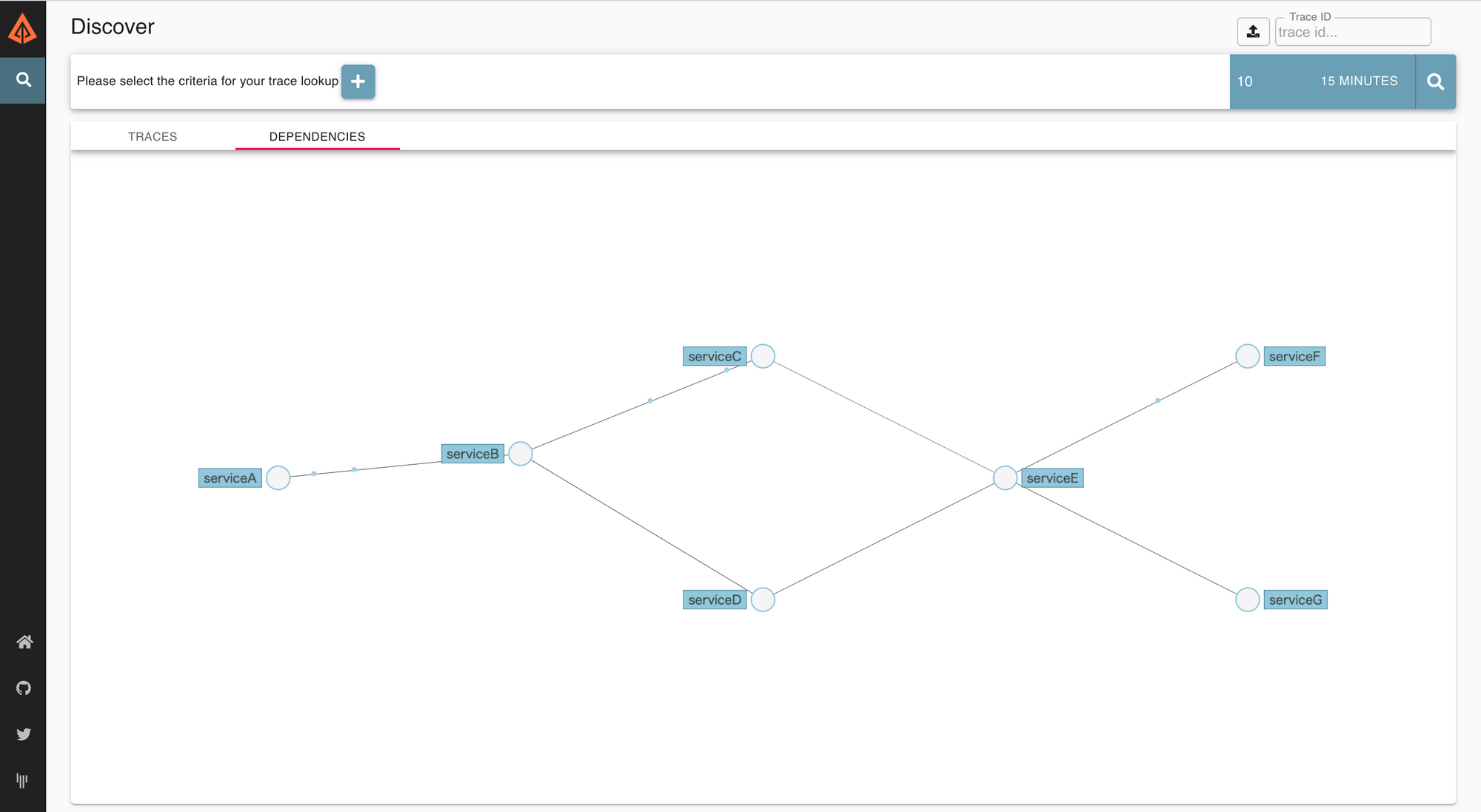
If loop exists in the dependency graph, we need to break them before making such an API available for consumption.
Circuit Breakers
For a tolling recharge/purchase to happen, Toll server talks to many services. Some of them are 3rd party services like banking servers. Many of the times, these 3rd party servers slip on SLA of APIs. This can cause lots of issues.
- Threads on our server calling these 3rd party services can get blocked waiting on replies. This can cause Thread pool and its queue to get exhausted very fast at high RPM. This will lead to unresponsive server and eventual crash.
- Any 5xx errors that get reported immediately from 3rd party servers can lead to zombie transactions where money goes on "hold" since we don't have updated correct status from said 3rd parties. This can lead to bad user experience
- Any unrecognised response from 3rd party APIs can also lead to #2
- If calls to 3rd party is async in nature, then queue build up will happen in above scenario of #1 and #2. This again leads to bad experience for user
To ensure our servers don't go down and at the same time give a good experience to users we adopted circuit breaker - Resilience4j
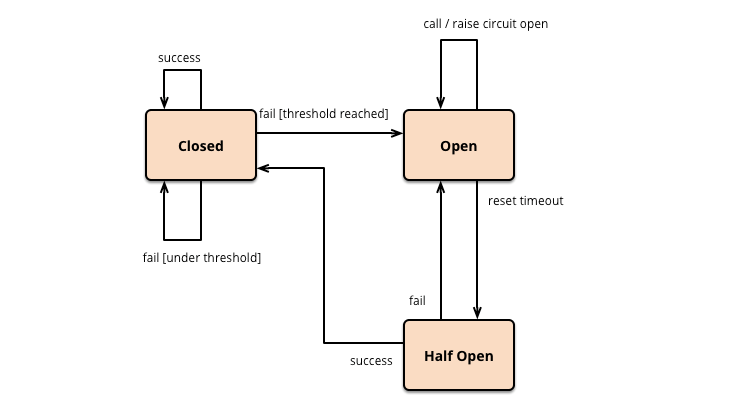
We have the logic defined at each 3rd party API level for API response time and error percentage on resilience. This ensures that whenever circuit is opened, we respond back to user with graceful info, and at the same time, prevent the server threads from choking. Timeouts are also defined for half-open circuit where we allow certain percentage of traffic to pass through to determine if the end point is stable enough. This has helped scaled our Toll server massively.
API Timeouts
Every API call your server makes needs to have a timeout defined as per functionality. This is a best practise which needs to be followed. If we fallback on default timeout (typically 60s on Java servers), this can cause server threads to choke. At BlackBuck we have defined custom Rest Templates within Sprint boot servers. All 3rd party API calls that are implemented on Toll, fall onto certain categories of Rest Templates.
Async Executor
By default Sprint boot provides default async executor if async has been enabled for the server. When writing async APIs, a good practise is to categorize them onto group of async executors on which they need to run rather than running them on default. This will prevent thread pool exhaustion and queue build up. Also, some 3rd party libraries can also end up using default async executor causing exhaustions which are hard to debug. Furthermore, if server goes down when messages are residing within Spring boot's queue, then this can also lead to data loss.
Enhanced Monitoring
At Blackbuck we use Newrelic for APM and Infra monitoring apart from AWS Cloudwatch. For purpose of toll scaling, we had to monitor how many active threads are getting utilized/remaining for server(Tomcat), async threads (for each executor) and DB threads (Hikari CP threads). By default they are not exposed to Newrelic. We exposed JMX beans on our SpringBoot server which measured the above required metrics. In times of eventual failures, these enhanced monitoring and alerts helped identify the issues on servers at least 5 mins before they actually happened, thereby preventing major downtimes.
We carried out performance testing using Apache JMeter. Currently BlackBuck's Toll servers are capable of scaling 50x of current RPM which is needed as significant portion of India's Trucking Toll transactions flow through these systems. There are many other nuances like Auto-scaling, Real-time alerting which have contributed to building stable and reliable Tolling platform for the Indian ecosystem.